关注公众号【算法码上来】,每日算法干货马上就来!

这周开始将会学到神经网络编程的基础知识。
2.1 二分分类
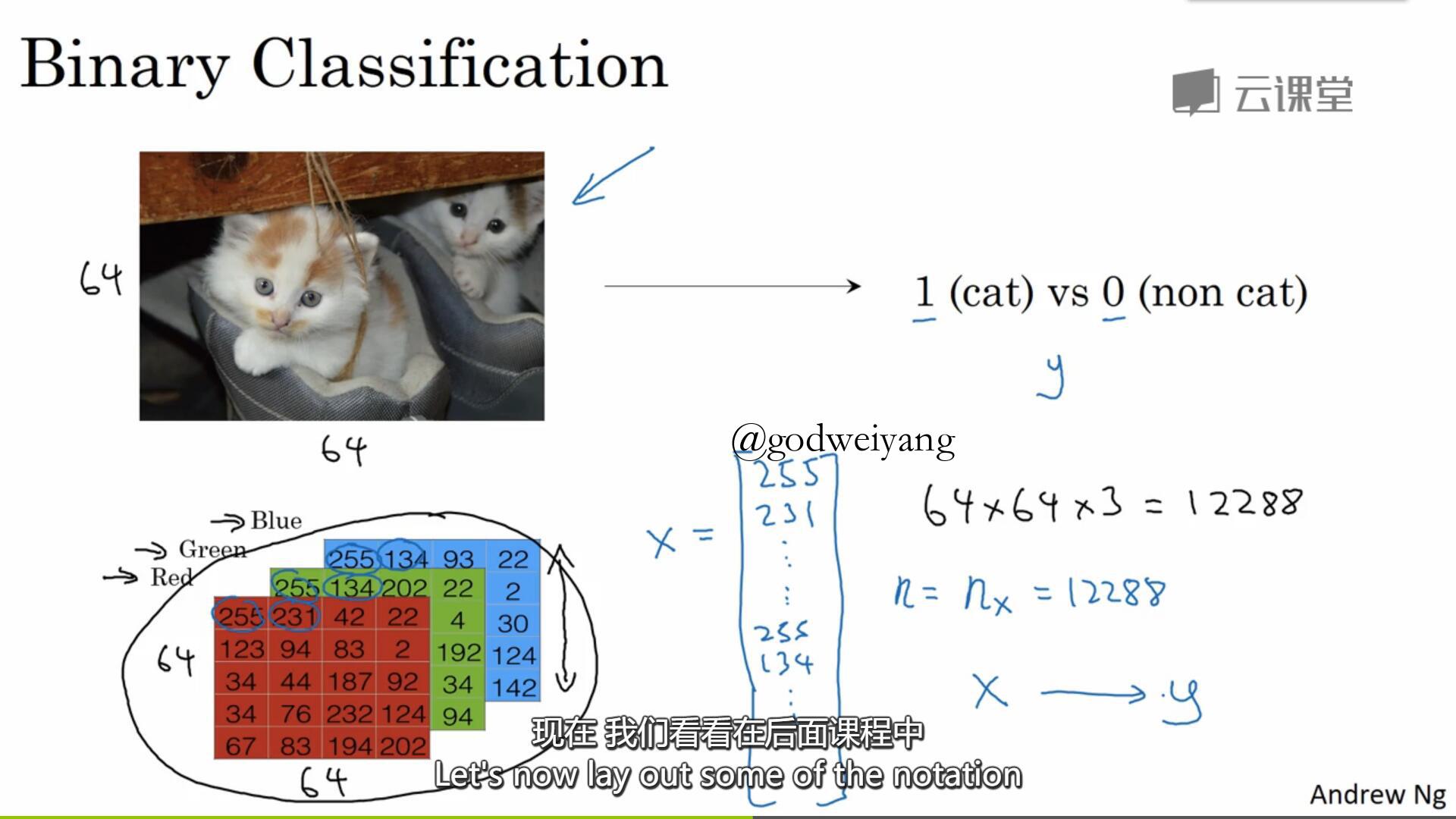
二分类问题就是给定一个输入$x$,预测它的标签$y$是0还是1。拿预测一张图片是不是猫来举例子,一张图片大小为${\rm{64}} \times {\rm{64}}$,将它转化为三个矩阵分别代表RGB分量。再将三个矩阵合并成一个大小为${\rm{(64}} \times {\rm{64}} \times {\rm{3,1)}}$的矩阵作为输入$x$。
下面给出一些以后要用到的符号表示。
一个样本用$(x,y)$表示,其中$x \in {R^{ {n_x}}}$,$y \in \{ 0,1\} $,那么$m$个训练样本就可以用集合$\\{ ({x^{(1)}},{y^{(1)}}),({x^{(2)}},{y^{(2)}}), \ldots ,({x^{(m)}},{y^{(m)}})\\} $来表示。
我们还可以将所有样本特征值用一个矩阵表示:
\[X = \left[ {\begin{array}{*{20}{l}} \vdots & \vdots & \cdots & \vdots \\\\{ {x^{(1)}}}&{ {x^{(2)}}}& \cdots &{ {x^{(m)}}}\\\\ \vdots & \vdots & \cdots & \vdots \end{array}} \right]\]
其中$X \in {R^{ {n_x} \times m}}$。
所有样本标签也可以用一个矩阵表示:
\[Y = \left[ {\begin{array}{*{20}{l}}{ {y^{(1)}}}&{ {y^{(2)}}}& \cdots &{ {y^{(m)}}}\end{array}} \right]\]
其中$Y \in {R^{1 \times m}}$。
2.2 logistic回归
logistic回归就是用线性函数来拟合输出标签。具体定义为,输入特征$X \in {R^{n_x}}$,参数$w \in {R^{n_x}}$,$b \in {R}$。那么令输出标签
\[{ {\hat y}^{(i)}} = \sigma ({w^T}{x^{^{(i)}}} + b)\]
其中\[\sigma ({x^{^{(i)}}}) = \frac{1}{ {1 + {e^{ - {x^{^{(i)}}}}}}}\]
2.3 logistic回归损失函数
损失函数衡量的是输出标签${\hat y}$与真实标签$y$之间的差距,有很多种定义方法,下面是常用的两种:
\[L({ {\hat y}^{^{(i)}}},{y^{^{(i)}}}) = \frac{1}{2}{({ {\hat y}^{^{(i)}}} - {y^{^{(i)}}})^2}\]和
\[L({ {\hat y}^{^{(i)}}},{y^{^{(i)}}}) = - [{y^{(i)}}\log ({ {\hat y}^{(i)}}) + (1 - {y^{(i)}})\log (1 - { {\hat y}^{(i)}})]\]
一般我们使用下面一种损失函数,具体原因最后一节课会讲到,因为它是个凸函数,方便梯度下降。
如果有$m$个样本,那么总的损失函数就定义为
\[J(w,b) = \frac{1}{m}\sum\limits_{i - 1}^m {L({ {\hat y}^{^{(i)}}},{y^{^{(i)}}})} = - \frac{1}{m}\sum\limits_{i - 1}^m {[{y^{(i)}}\log ({ {\hat y}^{(i)}}) + (1 - {y^{(i)}})\log (1 - { {\hat y}^{(i)}})]} \]
2.4 梯度下降法
通过重复
\[w: = w - \alpha \frac{ {\partial J(w,b)}}{ {\partial w}}\]
和
\[b: = b - \alpha \frac{ {\partial J(w,b)}}{ {\partial b}}\]
来不断更新$w$和$b$,使得$w$和$b$接近最优值。
2.7 计算图
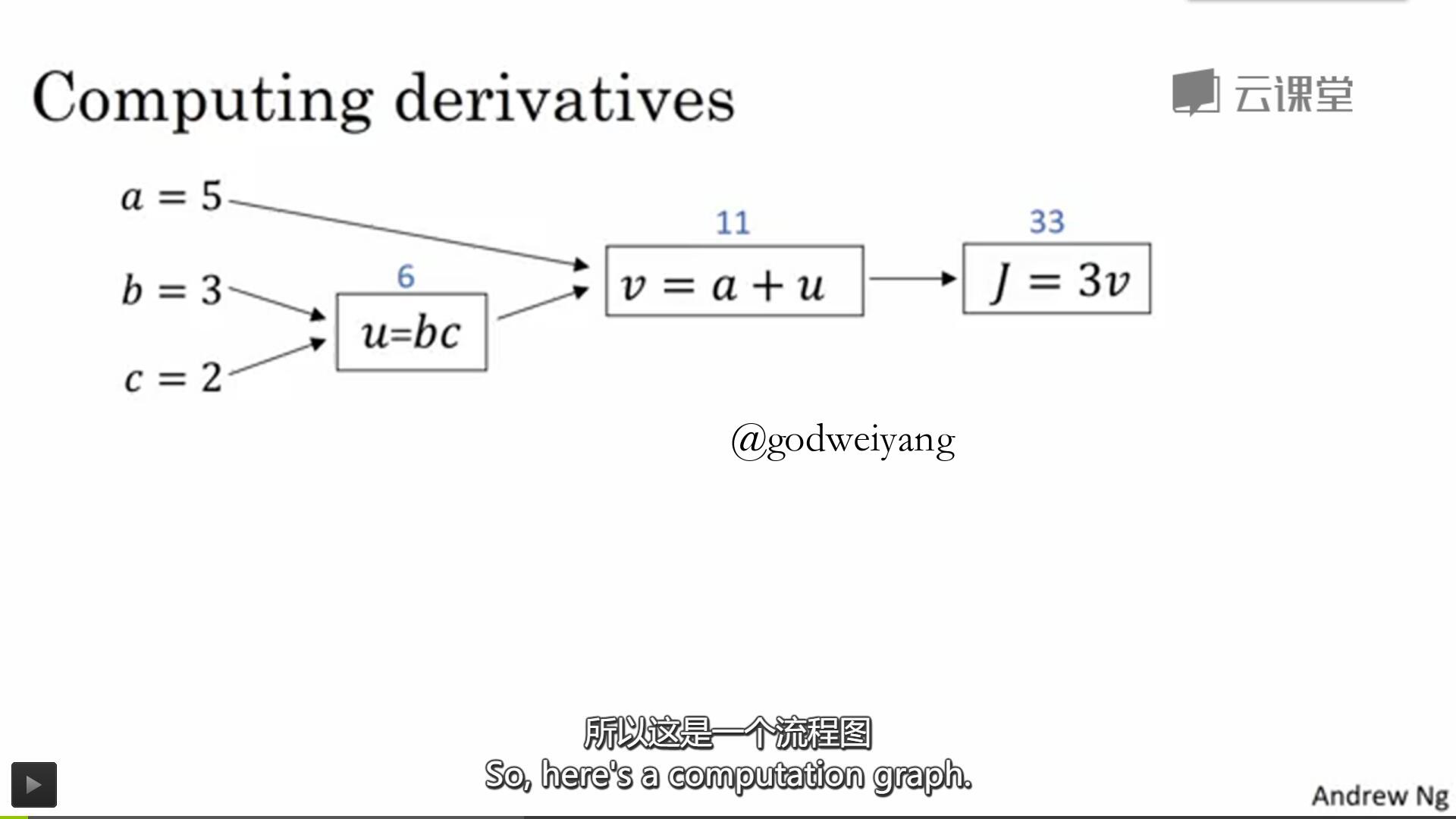
如上图所示就是一个计算图,初始结点都是输入值,中间一个结点表示一个运算,最后一个结点就是输出值。
2.8 计算图的导数计算

反向传播的时候只要沿着红色的箭头利用求导链式法则来对每个参数求导就行了。
2.9 logistic回归中的梯度下降

logistic回归的计算图如上图所示,导数如下:
\[\frac{ {\partial L(a,y)}}{ {\partial a}} = - \frac{y}{a} + \frac{ {1 - y}}{ {1 - a}}\]
\[\frac{ {\partial L(a,y)}}{ {\partial z}} = \frac{ {\partial L(a,y)}}{ {\partial a}} \cdot \frac{ {\partial a}}{ {\partial z}} = ( - \frac{y}{a} + \frac{ {1 - y}}{ {1 - a}}) \cdot a(1 - a) = a - y\]
\[\frac{ {\partial L(a,y)}}{ {\partial {w_1}}} = {x_1} \cdot \frac{ {\partial L(a,y)}}{ {\partial z}} = {x_1}(a - y)\]
\[\frac{ {\partial L(a,y)}}{ {\partial {w_2}}} = {x_2} \cdot \frac{ {\partial L(a,y)}}{ {\partial z}} = {x_2}(a - y)\]
\[\frac{ {\partial L(a,y)}}{ {\partial b}} = \frac{ {\partial L(a,y)}}{ {\partial z}} = a - y\]
2.10 $m$个样本的梯度下降

$m$个样本的梯度其实就是每个样本的梯度求和,如图所示的伪代码中,用一层for循环来对梯度进行求和。在后面的课程中我们将会摒弃这种做法,用更快速的向量化方法来进行计算。
2.11 向量化
向量化就是将例如${w^T}x$这样的矩阵点乘用python的numpy库函数dot代替普通的for循环。示例代码如下:
import numpy as np
a = np.random.rand(1000000)
b = np.random.rand(1000000)
c = np.dot(a, b)
print c2.12 向量化的更多例子
经验法则是能不使用for循环就尽量不要使用,用向量来代替。更多的向量化例子有np.exp(),np.sum()等等。
2.13 向量化logistic回归
之前提到的算法是用for循环来计算所有的${ {\hat y}^{(i)}} = \sigma ({w^T}{x^{^{(i)}}} + b)$。现在可以使用向量化来加快计算速度,只要计算$Y = \sigma ({w^T}X + b)$即可。
2.14 向量化logistic回归的梯度输出
logistic回归的梯度用向量可以表示为
\[dz = A - Y\]
\[dw = \frac{1}{m}Xd{z^T}\]
下面两节课都是讲的python的广播和向量的一些说明,在此就不细讲了,大家可以去查看python文档。其中讲到的一个写python程序的好习惯就是用到向量的时候如果不确定维数,那么你就reshape()一下,还有就是加一句assert()语句判断一下维数。




